Perspective Projection, Intrinsics, and Depth
This is Part 4 of the series:
- Understanding Camera Coordinate Transformations
- Orthographic Projection? 📸
- Viewport Transform for Orthographic LiDAR Projection
- Perspective Projection, Intrinsics, and Depth
- Orthographic vs Perspective: Scaling, the Perspective Divide, and Getting to Pixels
- Measuring Objects Viewed at an Angle in Perspective Images
- Z-Depth vs Euclidean Depth in Perspective Projection
Table of Contents
- Perspective Projection, Intrinsics, and Depth
- Table of Contents
- Glossary
- Assumptions
- Intro
- 1. The Intrinsic Matrix
- 2. Principal Point:
cx,cy - 3. Focal Length in Pixels:
fx,fy - 4. Pixel to Ray
- 5. Calculating the angle for a given ray from the principal ray
- 6. Where Depth Enters
- 7. Pixel Physical Size Calculation
- 8. Angular Size Plus Depth Becomes Meters
- 10. The Short Version
- Mermaid Diagrams
- References
Glossary
- Pinhole (Camera Center): The theoretical single point where all incoming light rays intersect before hitting the image sensor.
- Virtual Image Plane: A mathematical construct placed in front of the camera center. It represents the image correctly oriented (upright), rather than working with the physically upside-down image on the real sensor.
- Intrinsic Matrix: A matrix mapping 2D pixel coordinates to 3D viewing rays, containing the focal length and principal point.
- Principal Point ($c_x, c_y$): The physical "center of vision" on the sensor; the exact pixel where the camera looks directly straight ahead.
- Focal Length ($f_x, f_y$): The distance from the pinhole to the virtual image plane, measured in pixel units, which dictates the field of view.
- Depth Map: An array of values matching the image resolution where each pixel encodes the physical distance from the camera central point to the visible surface.
Assumptions
- This post assumes that depth is the Euclidean distance from the camera center to the object. Some libraries instead provide Z-depth, measured parallel to the camera's optical axis. See Z-Depth vs Euclidean Depth in Perspective Projection for the formulas and a worked example.
Intro
In the orthographic projection posts, the useful simplification was this:
A pixel can be treated as a constant-sized square in the real world.
That is why orthographic projection is easier for measurement. Once we know the scale, pixel distance can be converted back into real distance with simple multiplication.
Perspective projection breaks this assumption.
In perspective projection, a pixel is not a fixed-size square in the world. A pixel is more like a small direction coming out of the camera. Close to the camera, that direction covers a small physical area. Far away, the same direction covers a larger physical area. This is exactly how regular photography works.
Parallel train tracks

This is also how our eyesight works. In real world its not possible to directly obtain ortographic projection.
This is why an RGB-D measurement pipeline becomes important in real world. It combines
- image taken with perspective projection using camera intrinsics
- depth data (this can be from lidar, photogrammetry ...)
In essence
- The intrinsics tell us where a pixel is looking.
- The depth tells us how far away the object is at that pixel.
Together they let us estimate how large that pixel is in meters.
1. The Intrinsic Matrix
The camera intrinsic matrix usually looks like this:
$ K = \begin{pmatrix} f_x & 0 & c_x \\ 0 & f_y & c_y \\ 0 & 0 & 1 \end{pmatrix} $
For example, a calibrated camera might have this intrinsic matrix:
m = np.array([
[3003.1174, 0, 2011.17],
[0, 3003.1174, 1514.9209],
[0, 0, 1]
])
So:
fx = 3003.1174
fy = 3003.1174
cx = 2011.17
cy = 1514.9209
Definitions:
fx: focal length in pixels in the horizontal direction.fy: focal length in pixels in the vertical direction.cx: x-coordinate of the principal point, in pixels.cy: y-coordinate of the principal point, in pixels.
These four values define how image pixels relate to camera rays.
2. Principal Point: cx, cy
The principal point is:
The pixel where the camera is looking straight ahead.
It is located on the sensor. It is not exactly the same thing as the image center, although it is usually close.
The image center is just the geometric middle of the rectangular image:
image center = (image_width / 2, image_height / 2)
The principal point is physical:
principal point = where the lens optical axis hits the sensor
In a perfect camera, those would be exactly the same. In a real camera, the lens and sensor are not mounted with mathematical perfection, so calibration gives us the actual principal point.
For example, if an image is roughly 4032 x 3024, then the image center is:
(2016, 1512)
This example principal point is:
(2011.17, 1514.9209)
That is very close to the center, but not exactly. It is about 4.8 pixels left and 2.9 pixels down from the image center.
The useful mental model is:
(cx, cy) = the zero point for camera direction
If a pixel is exactly at (cx, cy), then it looks straight forward from the camera.
If a pixel is to the right of cx, then it looks a bit to the right.
If a pixel is to the left of cx, then it looks a bit to the left.
Same for cy vertically.
This is why the code uses:
x - cx
y - cy
It is asking:
How far is this pixel from the straight-ahead pixel?
3. Focal Length in Pixels: fx, fy
The values fx and fy are focal lengths, but measured in pixels.
That sounds strange at first because focal length is often described in millimeters. But for image geometry, pixel units are more practical.
In the ideal pinhole camera model, focal length means the forward distance from the pinhole to the image plane.
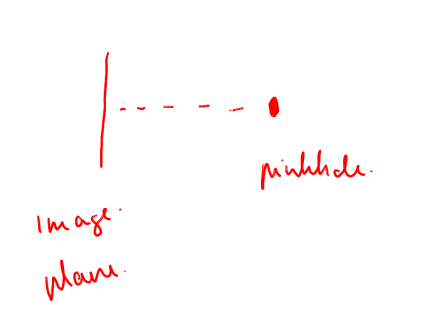
What focal length really does
fxis the horizontal version. It tells us how much moving left or right in the image changes the left-right viewing angle.fyis the vertical version. It tells us how much moving up or down in the image changes the up-down viewing angle.
Large fx means:
same pixel offset = smaller angle
That is like a zoomed-in / narrow field-of-view camera.
Small fx means:
same pixel offset = larger angle
That is like a wide-angle camera.
The same applies to fy, but vertically.
In this example, fx and fy are equal:
fx = fy = 3003.1174
That means this example assumes the camera has the same scaling horizontally and vertically. In practical terms, square pixels and symmetric focal scaling. This is commonly assumed.
4. Pixel to Ray
First let's talk about the virtual image plane
In the pinhole camera model, the real image sensor sits behind the small camera hole / camera center.
That real image plane receives an upside-down version of the world, because light rays cross at the pinhole before they hit the sensor.
For geometry, that flipped picture is annoying. So instead of drawing the image plane behind the pinhole, we usually draw a virtual image plane in front of the pinhole, between the camera and the scene.
It represents almost the same thing as the actual image plane, but inverted to the front side:
scene
|
|
virtual image plane
|
camera center / pinhole
|
real image plane / sensor
The virtual image plane is not a physical surface inside the camera. It is a mathematical helper. It lets us say that a pixel is in front of the camera and that the ray goes from the camera center through that pixel into the world.
- It is the same distance from the pinhole as the real image plane is
So the virtual image plane is basically the real image plane mirrored through the pinhole. Same projection idea, but with the inconvenient upside-down sensor image turned into a forward-facing construction.
Pixel to Ray
In practical terms, a ray is built like this
ray_center = np.array([x - cx, y - cy, fx])
"ray_center" means the point on the virtual image plane that the ray passes through, measured relative to the pinhole/camera center.
The components mean:
| Term | Meaning |
|---|---|
x - cx |
horizontal offset from straight ahead |
y - cy |
vertical offset from straight ahead |
fx |
forward direction / focal length in pixel units |
If the pixel is at the principal point ($x = c_x,\ y = c_y$), then:
ray_center = [0, 0, fx]
That ray points straight forward.
If the pixel is 100 pixels to the right ($x = c_x + 100,\ y = c_y$), then:
ray_center = [100, 0, fx]
That ray points forward and slightly right.
So the intrinsic matrix lets us turn a pixel coordinate into a camera ray.
This is the first half of the perspective-measurement trick.
Those coordinates do not say where the object is in 3D. They say which direction the camera is looking for that pixel.
After normalization:
d = normalize([x - cx, y - cy, f])
we get a unit ray direction d from the camera center.
So one RGB pixel really means:
The object is somewhere along this ray — not that the object is exactly at one point.
A normal RGB image gives color at each pixel, but it does not give the depth of the visible surface. One pixel therefore corresponds to infinitely many possible 3D points along the same ray (see Diagram 1 at the end of this post).
5. Calculating the angle for a given ray from the principal ray
Once we have a ray, we often want its angle away from straight ahead. This is useful because it tells us how far off-axis the camera is looking for a given pixel.
- The ray is built from two pieces of information:
pixel offset = how far the pixel is from the principal point
focal length = forward distance to the virtual image plane
These two form a right triangle:
- the opposite side is the pixel offset (
x - cxhorizontally, ory - cyvertically), - the adjacent side is the focal length (
fxorfy).
The tangent of the ray angle is then simply the offset divided by the focal length:
$ \tan(\theta_x) = \frac{x - c_x}{f_x} \qquad \tan(\theta_y) = \frac{y - c_y}{f_y} $
Taking the inverse tangent gives the angle itself:
$ \theta_x = \arctan\!\left(\frac{x - c_x}{f_x}\right) \qquad \theta_y = \arctan\!\left(\frac{y - c_y}{f_y}\right) $
A pixel at the principal point gives an offset of 0, so the angle is 0 (straight ahead). The farther the pixel sits from the principal point, the larger the angle.
6. Where Depth Enters
The depth data answers a different question:
How far away is the visible surface at this pixel?
So for a pixel (x, y), the depth map might say:
depth = 2.0 meters
In short
The intrinsic matrix gives the direction.
The depth map gives the distance.
This is why LiDAR matters. In a normal RGB image, we see the pixel, but we do not directly know how far away the object is. With LiDAR/depth, we get that missing scalar.
If:
C = camera center - Also known as the pinhole.
d = ray normalized
z = depth obtained
p = actual 3D point
then the reconstruction idea is of a point in point cloud is:
p = C + z d
7. Pixel Physical Size Calculation
Tangent reminder
Almost every step in this post uses a right triangle: the focal length is the forward (adjacent) side, and the pixel offset is the sideways (opposite) side.
The tangent of an angle is just the ratio of those two sides:
$ \tan(\theta) = \frac{\text{opposite}}{\text{adjacent}} $
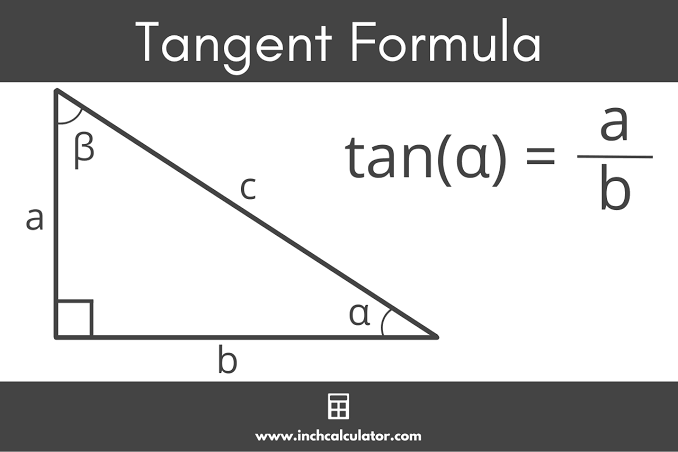
So if we know the pixel offset and the focal length, we get the tangent of the ray angle directly. To recover the angle itself, we use the inverse, the arctangent:
$ \theta = \arctan\!\left(\frac{\text{opposite}}{\text{adjacent}}\right) $
Two facts are enough for this tutorial:
tantakes an angle and returns a length ratio. Larger angle, larger ratio.arctandoes the reverse: it takes a ratio and returns an angle.
That is why pixel offsets divided by focal length give angles via arctan, and angles multiplied back through tan give physical sizes. Tangent and arctangent are the bridge between pixels and angles in both directions.
Calculation itself
To estimate that pixel footprint, we compare the off-axis angle of one pixel with the off-axis angle of its immediate neighbors. From earlier, let $\theta_x$ and $\theta_y$ denote the horizontal and vertical off-axis angles of a ray from the principal point:
$ \theta_x = \arctan\!\left(\frac{x-c_x}{f_x}\right), \qquad \theta_y = \arctan\!\left(\frac{y-c_y}{f_y}\right) $
So the one-pixel angular step can also be written as:
$ \Delta\theta_x = \left|\arctan\!\left(\frac{x+1-c_x}{f_x}\right) - \arctan\!\left(\frac{x-c_x}{f_x}\right)\right| $
$ \Delta\theta_y = \left|\arctan\!\left(\frac{y+1-c_y}{f_y}\right) - \arctan\!\left(\frac{y-c_y}{f_y}\right)\right| $
These two values are the angular width and angular height of that pixel.
8. Angular Size Plus Depth Becomes Meters
After the code has:
angle_x_scale— angular width of the pixel ($\Delta\theta_x$)angle_y_scale— angular height of the pixel ($\Delta\theta_y$)depth— distance to the surface at that pixel ($d$)
it computes:
$ \text{width}_m = 2 \, d \, \tan\!\left(\frac{\Delta\theta_x}{2}\right) \qquad \text{height}_m = 2 \, d \, \tan\!\left(\frac{\Delta\theta_y}{2}\right) $
Step 1
- Division by 2 of the angle: $\dfrac{\Delta\theta}{2}$
The division by two actually comes from the fact that we have two rays. We calculate the angular width between the two rays, and these rays point to the center of each pixel.For our pixel, this means that we actually care for only the angle between our pixel ray center and our pixel edge.Now we have the angle between the pixel center ray and the pixel edge ray. We use the tangent of that to get the distance and multiply that with two.
Step 2
- $\tan(\theta)$
with tangent of angle we get relation between opposite side (pixel width) and adjacent side (pixel depth)
Step 3
- $d\,\tan(\theta)$
$ \tan(\theta) = \frac{\text{opposite}}{\text{adjacent}}, \qquad d = \text{adjacent} $
here we leverage the connection tan and angle have with ratio between right triangle sides, if we have ratio and one side available, we can derive the other side.
We multiply the distance by the ratio of opposite/adjacent:
$ \text{opposite} = \text{adjacent} \times \frac{\text{opposite}}{\text{adjacent}} $
Overall
The intuition is simple:
Physical size grows with distance.
So for a pixel with the same angular width:
| Distance | Real-world width |
|---|---|
| 1 meter | small |
| 5 meters | larger |
This is the exact point where intrinsics and depth are combined:
- The intrinsics produce the angular size.
- The depth scales that angular size into meters.
10. The Short Version
- The intrinsic matrix tells us: where is straight ahead, and how much a pixel offset changes the viewing angle.
- Depth tells us: how far away the object is at that pixel.
- Together: intrinsics + depth = a metric interpretation of an image pixel.
In one sentence:
The intrinsic matrix turns pixels into rays, and the depth map tells where those rays hit the object.
That is the core idea behind perspective area calculation with depth.
Mermaid Diagrams
Diagram 1
graph LR
P["Pixel (x, y)"] --> R["Ray direction d"]
R --> D1["Point at depth = 1 m"]
R --> D2["Point at depth = 3 m"]
R --> D3["Point at depth = 7 m"]
R -.-> Dn["...infinitely many"]